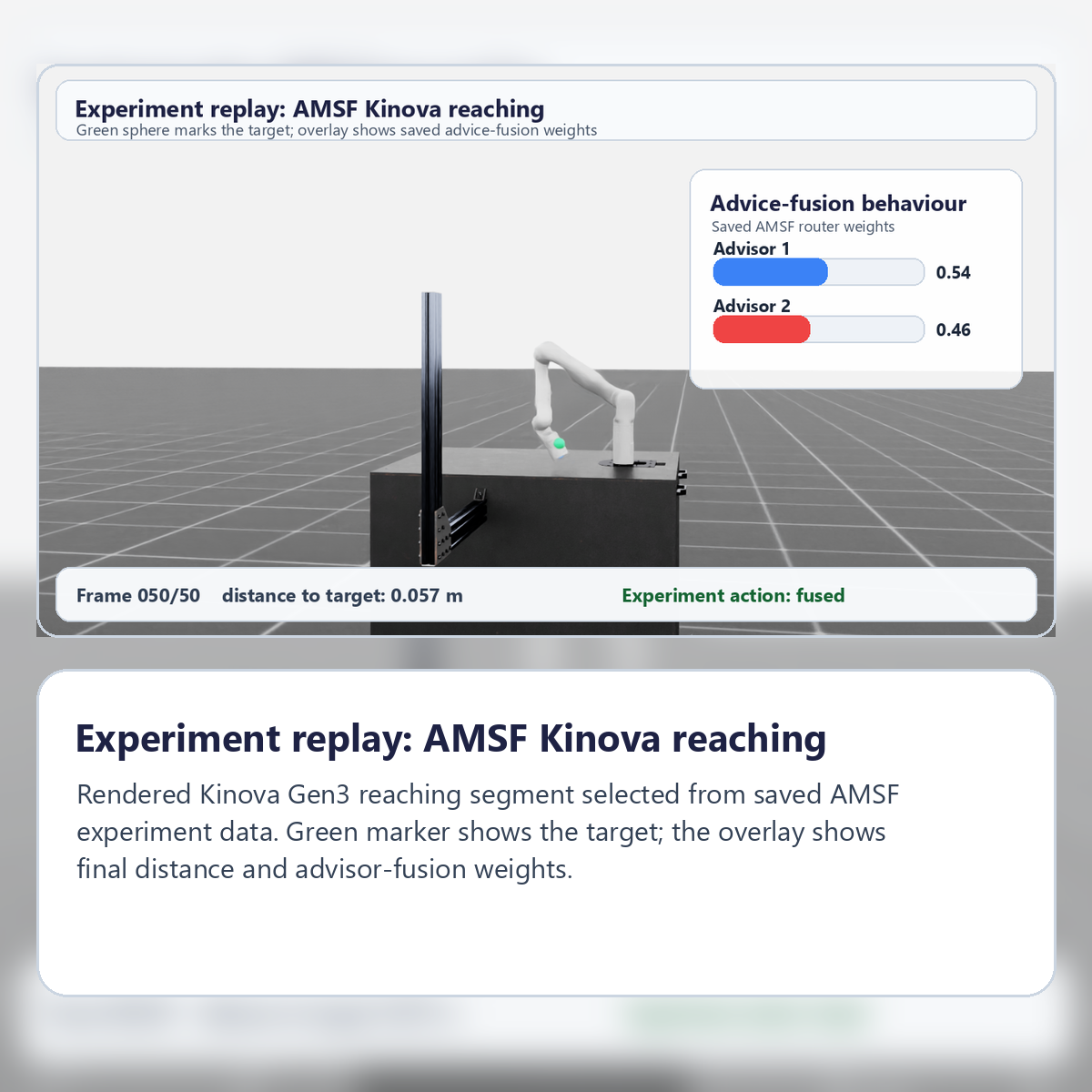
Adaptive Multi-Source Fusion for Interactive Reinforcement Learning

This project investigates how reinforcement learning agents can learn effectively from multiple imperfect sources of guidance. Rather than assuming that advice sources are uniformly reliable, the project studies how the structure of their errors affects learning, and develops adaptive fusion methods that decide when and how to use different sources of advice. Date: 2025 - 2028 Persons participating in the project:
- PIs: Dr. Francisco Cruz, Dr. Pamela Carreno-Medrano, Prof. Claude Sammut
- Associates: Maher Mesto
- Corresponding contact: m.mesto@unsw.edu.au
- Interactive reinforcement learning
- Human-guided reinforcement learning
- Multi-source advice
- Adaptive fusion
- Ambiguity reduction
- Robot learning
- Deep reinforcement learning
- Soft actor-critic
- Continuous control
| Selected Publications | Web |
|---|---|
| Mesto, M., & Cruz, F. (2025, November). The Consensus Paradox: When Low Disagreement Leads to Catastrophic Failure in Multi-teacher Reinforcement Learning. In Australasian Joint Conference on Artificial Intelligence, (pp. 426-438). Singapore: Springer Nature Singapore. Best paper award. | |
| Mesto, M., & Cruz, F. (2025). Conservative Bias in Multi-Teacher Learning: Why Agents Prefer Low-Reward Advisors. In Proceedings of the Australasian Conference on Robotics and Automation (ACRA), 2025. | |